|
I'm a research director at Naver AI Lab, working on various machine learning models towards real-world applications. At Naver, I've worked for network architectures (ReXNet, PiT), training techniques (CutMix, ReLabel, AdamP, KD), and robustness (ReBias). I've also participated on Naver's OCR (e.g., CRAFT, STR, Donut), face recognition, and LLMs (Cream) products. I received my MS, and PhD in computer vision at Seoul National University in 2013 and 2017, respectively, under supervision of Prof. Jin Young Choi. I received my BS from Seoul National University in 2010. I'm also an adjunct professor at SNU AI Inst. from Sep 2022, continuing my previous position at SNU CSE Dept (Sep 2021 - Aug 2022). Email / CV / Google Scholar / Github |

|
|
|
I am interested in training robust, generalizable, and transferable ML models (including vision, language, and vision-language models) for real-world applications. |
|
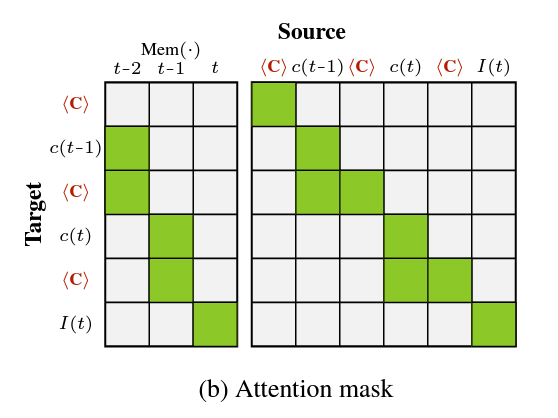
Jang-Hyun Kim, Junyoung Yeom, Sangdoo Yun*, Hyun Oh Song*. ICLR, 2024 arXiv / Bibtex / Code How can we use infinitly long contexts for LLMs? Inspired from the gist token, we propose an online context compression method. Our method can compress accumulated attention KVs into few [comp] tokens with 5x smaller context memory size. |
|
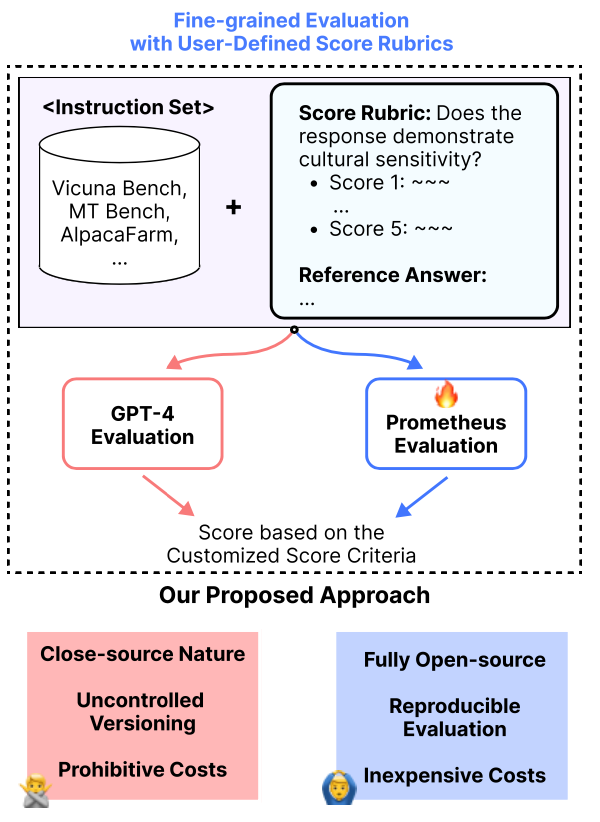
Seungone Kim*, Jamin Shin*, Yejin Cho*, Joel Jang, Shayne Longpre, Hwaran Lee Sangdoo Yun, Seongjin Shin, Sungdong Kim, James Thorne, Minjoon Seo ICLR, 2024 arXiv / Bibtex / Code We introduce Prometheus, a fully open-sourced LLMs with GPT-4 compatible evaluation performance. We built the Feedback Collection dataset, which is also open-sourced, including more than 20K instructions and 100K responses. |

|
Geewook Kim, Hodong Lee, Daehee Kim, Haeji Jung , Sanghee Park, Yoonsik Kim, Sangdoo Yun, Taeho Kil, Bado Lee, Seunghyun Park EMNLP, 2023 arXiv / Bibtex / Code / Demo After introducing Donut, we build Cream🍦 which leverages large language models (LLMs). To mitigate the gap between vision encoders and LMs, we propose auxiliary encoders and contrastive learning scheme. Cream demonstrates robust and impressive document understanding performance. |

|
Siwon Kim, Sangdoo Yun, Hwaran Lee, Martin Gubri, Sungroh Yoon, Seong Joon Oh. NeurIPS, 2023 (Spotlight) arXiv / Bibtex / tweet Code / Demo Perhaps, Large language models (LLMs) can answer just about anything, with their hyper-scale parameters and data. However, they may answer your private information (i.e., personally identifiable information (PII)), then it could be problematic. With our probing tool, ProPILE, we can investigate whether the model reveals our personal information or not. |

|
Jang-Hyun Kim, Sangdoo Yun, Hyun Oh Song. NeurIPS, 2023 arXiv / Bibtex / Code Problematic data (e.g., outlier data or incorrect labels) harm model performance and robustness. However, identifying such problematic data in large-scale datasets is quite challenging. Our solution focuses on the relationship among data, particularly in the feature space. By utilizing our relation graph, we can easily determine whether a data point is an outlier, has a misassigned label, or is perfectly fine. |

|
Geonmo Gu*, Sanghyuk Chun*, Wonjae Kim, HeeJae Jun, Yoohoon Kang, Sangdoo Yun. *Equal contribution arXiv, 2023 arXiv / Bibtex / Code / Demo We propose a diffusion-based model, CompoDiff, for Composed Image Retrieval (CIR) task. To train the model, we created a new dataset comprising 18 million triplets of images and associated conditions. CompoDiff shows state-of-the-art zero-shot CIR performance. |
|
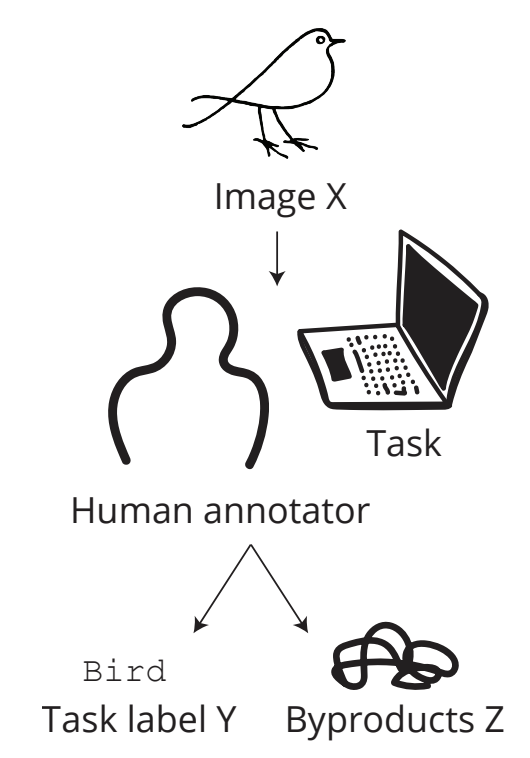
Dongyoon Han*, Junsuk Choe*, Dante Chun, John Joon Young Chung, Minsuk Chang, Sangdoo Yun, Jean Y. Song, Seong Joon Oh. *Equal contribution ICCV, 2023 arXiv / cvf / Bibtex / Code & Dataset / Video When annotating data, annotators unintionally generate auxiliary information during the annotation task, such as mouse traces, mouse clicks, time durations. We call them annotation byproducts (AB). We propose the new paradigm of learning using annotation byproducts (LUAB) which can enhance robustness of image classifiers by aligning them with human recognition mechanisms. |
|
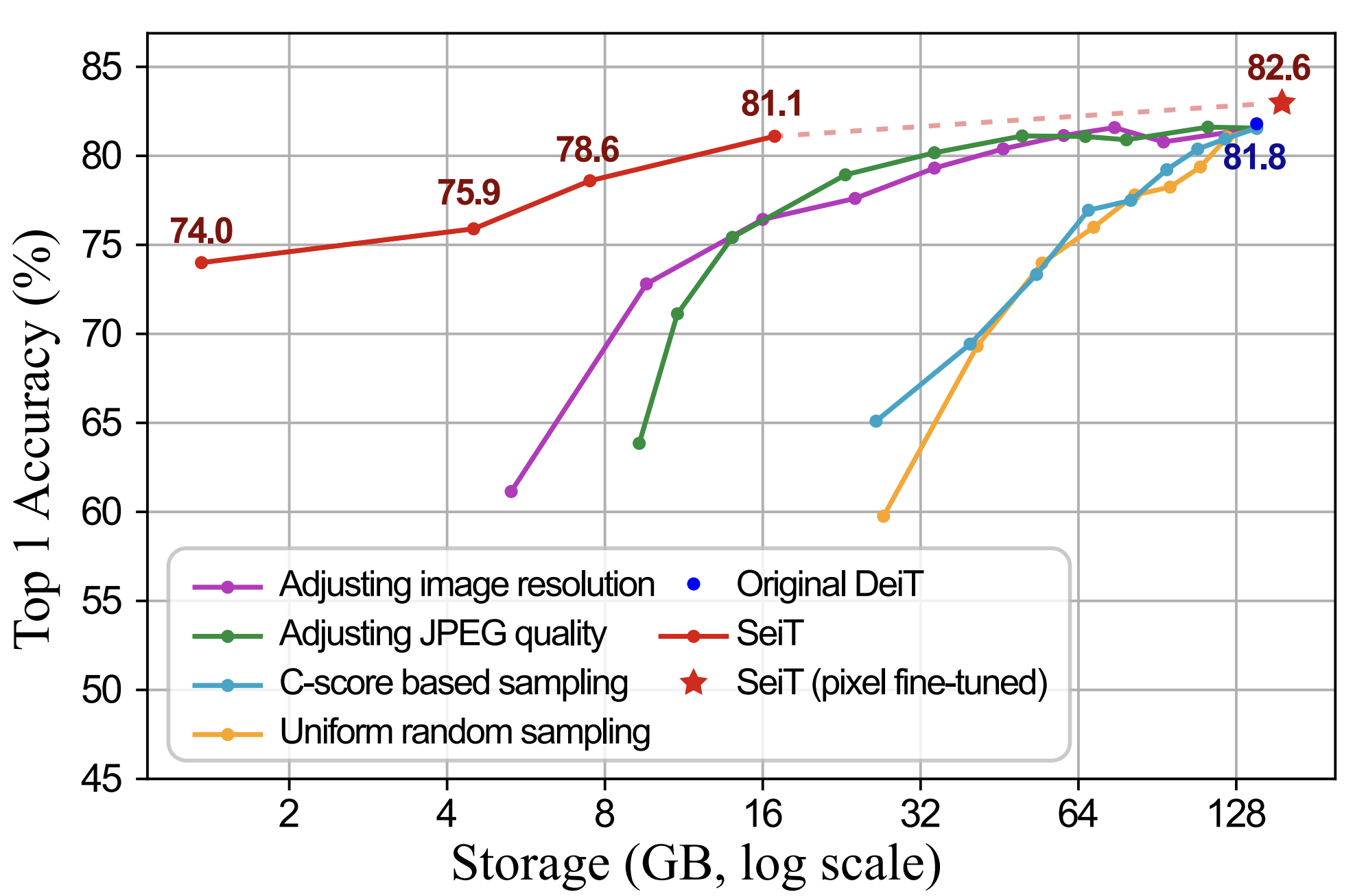
Song Park*, Sanghyuk Chun*, Byeongho Heo, Wonjae Kim, Sangdoo Yun. *Equal contribution ICCV, 2023 arXiv / cvf / Bibtex / Code Vision deep models are image data hungry, but image storage has become a bottleneck (e.g., LAION-5B images require 240 TB). We propose a storage-efficient training method, SeiT, that utilizes only 1% of standard pixel storage without sacrificing accuracy. |

|
Jaewoo Ahn, Yeda Song, Sangdoo Yun, Gunhee Kim. ACL, 2023 arXiv / Bibtex / Code Building persona is crucial for personalized dialog sistem. We explore additional vision modality beyond text-based persona. To this end, we collect multimodal persona dialog dataset (MPChat) and demonstrate how vision modality help the conversation. |
|
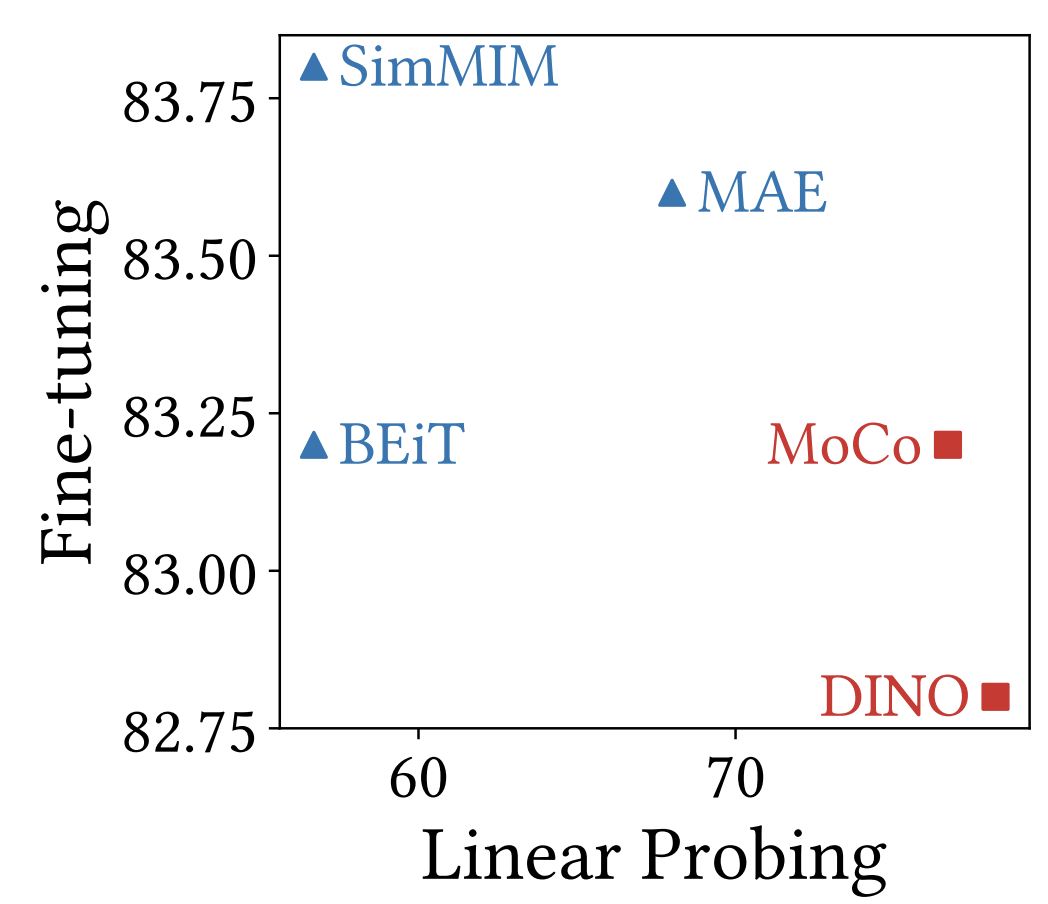
Namuk Park, Wonjae Kim, Byeongho Heo, Taekyung Kim, Sangdoo Yun. ICLR, 2023 OpenReview / Poster / Slide / arXiv / Bibtex / Code What are the differences between contrastive learning (CL) and masked image modeling (MIM)? Our findings indicate that: (1) CL captures global patterns more effectively than MIM, (2) CL learns shape-oriented features while MIM focuses on texture-oriented features, and (3) CL plays a key role in later layers, whereas MIM is more concentrated on early layers. |

|
Taeoh Kim, Jinhyung Kim, Minho Shim, Sangdoo Yun, Myunggu Kang, Dongyoon Wee, Sangyoun Lee. ICLR, 2023 (Notable Top 25%) OpenReview / arXiv / Bibtex We introduce DynaAugment, a new video data augmentation to capture the temporal dynamics in videos. DynaAugment changes the magnitude of augmentation operation over time to emulate temporal dynamics found in real-world videos. |

|
Chanwoo Park*, Sangdoo Yun*, Sanghyuk Chun. *Equal contribution NeurIPS, 2022 OpenReview / arXiv / Poster / Bibtex / Code Mixed sample data augmentation (MSDA), such as mixup and CutMix, has become a de facto strategy, but its understanding is not studied deeply yet. We introduce the first unified theoretical analysis for MSDAs and figure out what is the difference between mixup and CutMix. Up on the analysis, we build a simple hybrid version of mixup and CutMix to leverage the advantages of mixup and CutMix. |
|
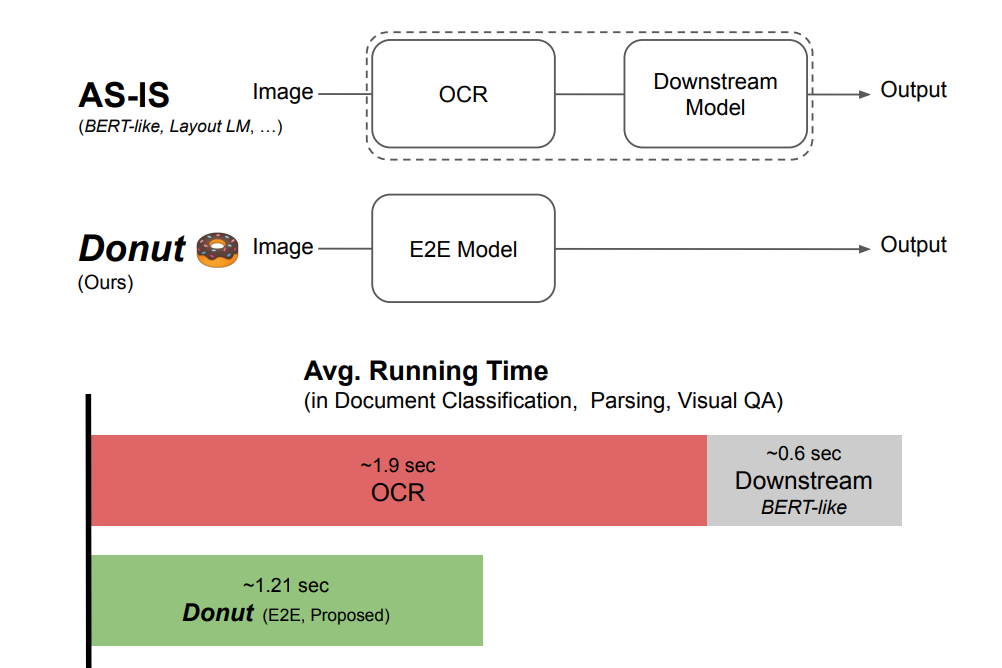
Geewook Kim, Teakgyu Hong, Moonbin Yim, Jinyoung Park, Jinyeong Yim, Wonseok Hwang, Sangdoo Yun, Dongyoon Han, Seunghyun Park ECCV, 2022 arXiv / Bibtex / Code Current visual document understanding (VDU) models heavily rely on external OCR framework (e.g., text detection, text recognition). OCR is expensive and sometimes not available. We bravely remove the dependency of OCR by modeling a simple transformer architecture. Take our highly efficient and powerful VDU model, Donut 🍩! |

|
Jang-Hyun Kim, Jinuk Kim, Seong Joon Oh, Sangdoo Yun, Hwanjun Song, Joonhyun Jeong, Jung-Woo Ha, Hyun Oh Song. ICML, 2022 Bibtex / Code Data condensation is a trick to compress training data by synthesizing them into several images. The goal is to obtain higher performance with lower consumption of data storage. We propose practical tricks for data condensation to bring it into more practical real-world settings (e.g., 224x224 size with ImageNet) beyond previous toy-ish settings (e.g., 32x32 size with CIFARs). |
|
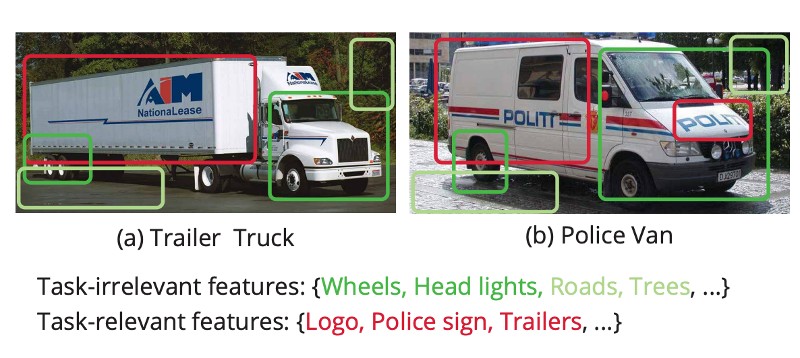
Saehyung Lee, Sanghyuk Chun, Sangwon Jung, Sangdoo Yun, Sungroh Yoon. ICML, 2022 Bibtex Existing data condensation methods deal with class-wise gradients and ignore the inter-class information. We show it would degrade performance in practical scenarios like fine-grained classification. Our simple remedy is modifying the loss function to integrate contrastive signals, which shows effectiveness in several practical scenarios. |
|
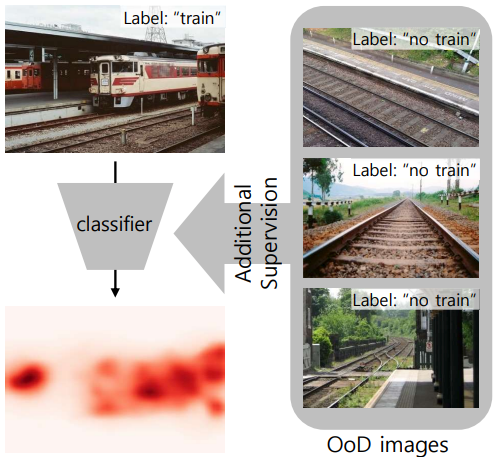
Jungbeom Lee, Seong Joon Oh, Sangdoo Yun, Junsuk Choe, Eunji Kim, Sungroh Yoon. CVPR, 2022 Bibtex / Code Weakly supervised semantic segmentation (WSSS) suffers from spurious correlations between foreground (e.g., train) and background (e.g., rail). Our idea is to collect background images without any foreground pixels (e.g., collecting railroad images without trains). Then we teach the model not to see the background pixels to classify foreground class. Adding small amount of background images brings large performance gain in WSSS. |
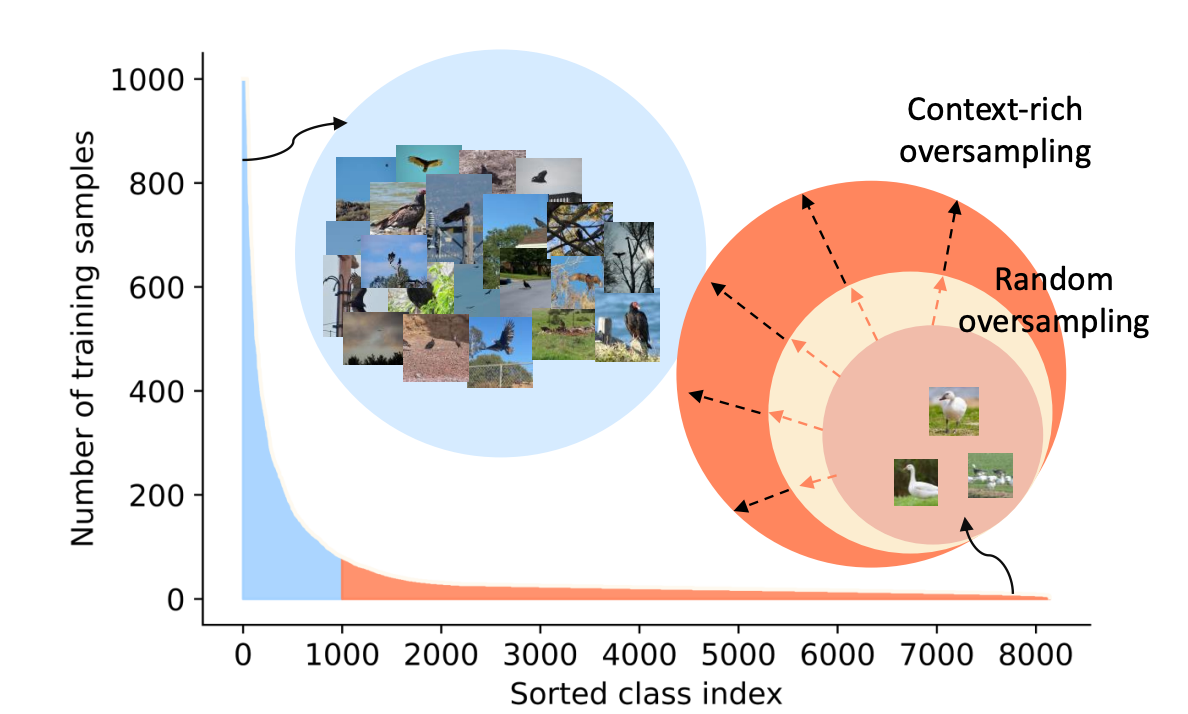
|
Seulki Park, Youngkyu Hong, Byeongho Heo, Sangdoo Yun, Jin Young Choi. CVPR, 2022 Bibtex / Code Data oversampling is a simple solution for long-tailed classification, but it may exacerbate overfitting with limited context information. Motivated from CutMix, we introduce a simple context-rich oversampling method. Interestingly, majority classes play a key role for boosting classification accuracy of minority classes! |
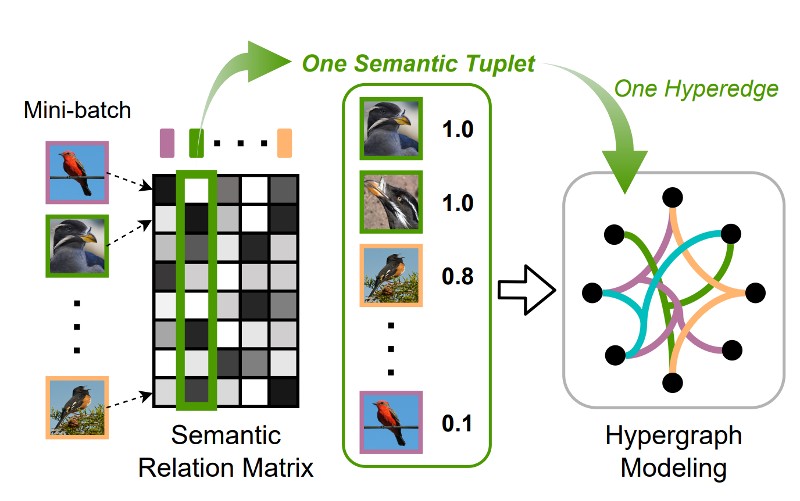
|
Jongin Lim Sangdoo Yun, Seulki Park, Jin Young Choi. CVPR, 2022 Bibtex / Code We formulate deep metric learning as a hypergraph node classification problem to capture multilateral relationship by semantic tuples beyond previous pairwise relationship-based methods. |
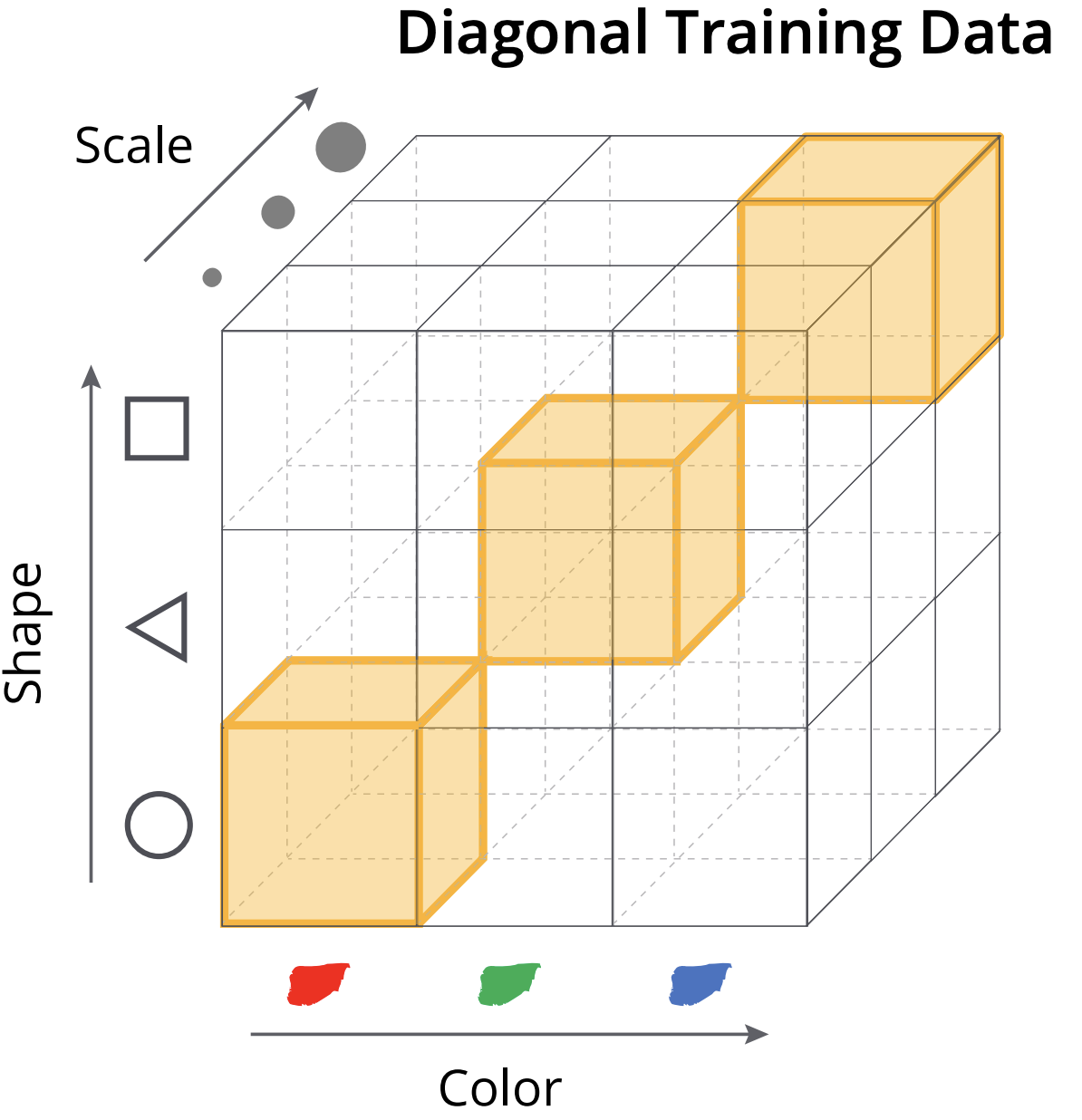
|
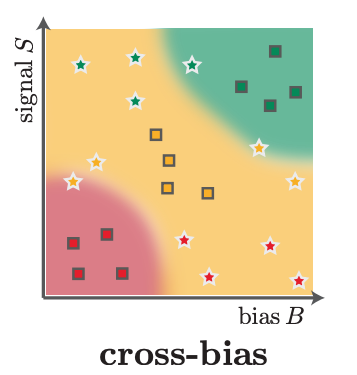
Luca Scimeca*, Seong Joon Oh*, Sanghyuk Chun, Michael Poli, Sangdoo Yun. *Equal contribution ICLR, 2022 Bibtex / OpenReview What causes shortcut learning problem? We observe the model's behaviors when we provide equal chance of being fit to multiple cues (e.g., color and shape with equal chance). Interestingly, the model would like to fit into a certain cue (e.g., color than shape) in such even situation. This paper explains the reason in terms of parameter-space perspective. |

|
Junho Cho, Sangdoo Yun, Dongyoon Han, Byeongho Heo, Jin Young Choi. IEEE Access, 2021 Bibtex Unifyied text detection and text removal framework for scene text removal in the wild. |
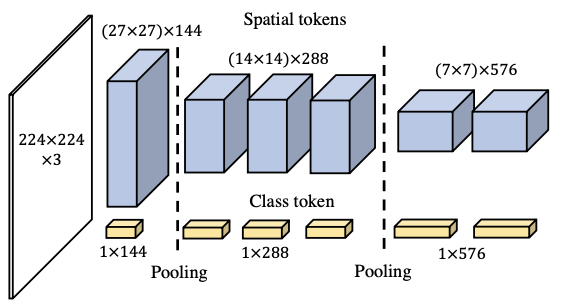
|
Byeongho Heo, Sangdoo Yun, Dongyoon Han, Sanghyuk Chun, Junsuk Choe, Seong Joon Oh. ICCV, 2021 Bibtex / Code The Vision transformer (ViT) has become a strong design principle for vision modeling. Because ViT is originated from NLP's Transformer, it has no intermediate pooling layers, which is common in CNNs. We simply inject the pooling concept on ViT and introduce a new architecture PiT. |
|
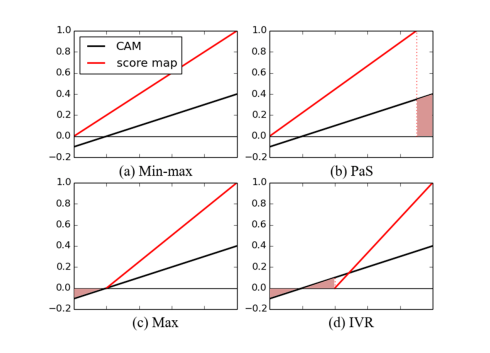
Jeesoo Kim, Junsuk Choe, Sangdoo Yun, Nojun Kwak. ICCV, 2021 Bibtex / Code We investigates the effect of CAM (CVPR'16) normalization on WSOL, and suggest a new normalization method. |

|
Sangdoo Yun, Seong Joon Oh, Byeongho Heo, Dongyoon Han, Junsuk Choe, Sanghyuk Chun. CVPR, 2021 Bibtex / Code / Video / Poster ImageNet has lots of label noises and there have been efforts to fix them on the evaluation set (e.g. Shankar et al., Bayer et al.). We paid our attention to the training set, whose label noises have been overlooked, and release the re-labeled ImageNet and codebase (published at this repo). The re-labeled data improves the ImageNet and downstream task accuracies. |
|
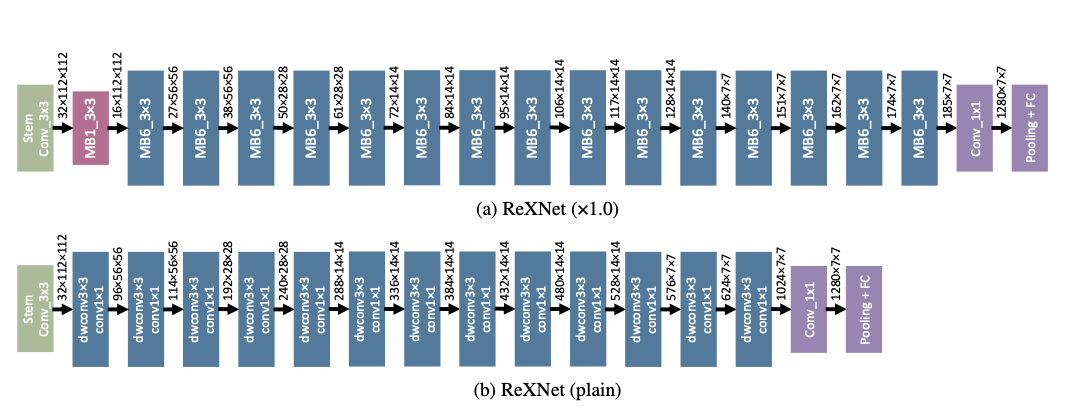
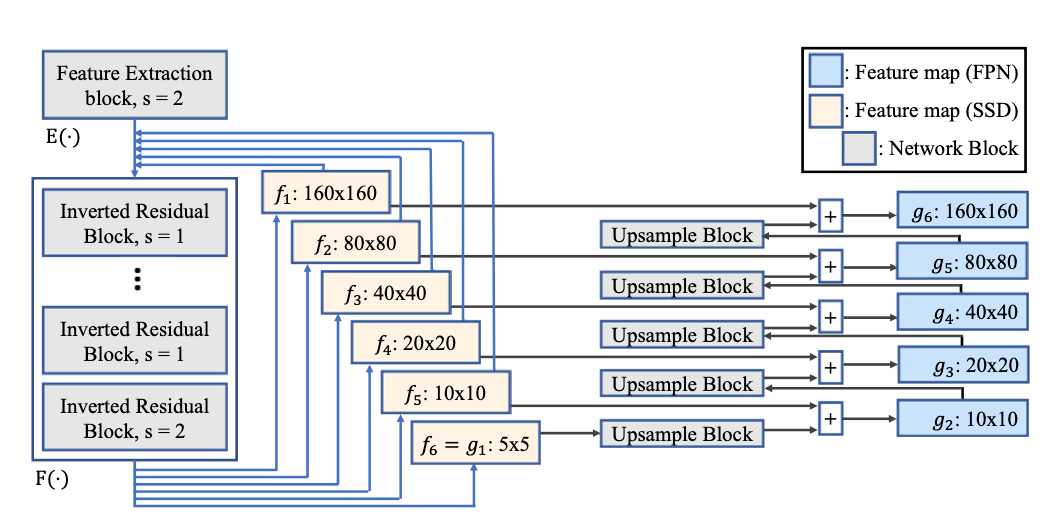
Dongyoon Han, Sangdoo Yun, Byeongho Heo, Youngjoon Yoo. CVPR, 2021 Bibtex / Code CNN architectures (e.g., ResNet, MobileNet, etc.) usually follows the same feature-map down-sampling policy. We conjecture such design policy would harm the representation ability of intermediate layers. We analyze the feature-map's rank (inspired by softmax-bottleneck) and suggests a new network architecture, namely, Rank eXpanded Network (ReXNet). |
|
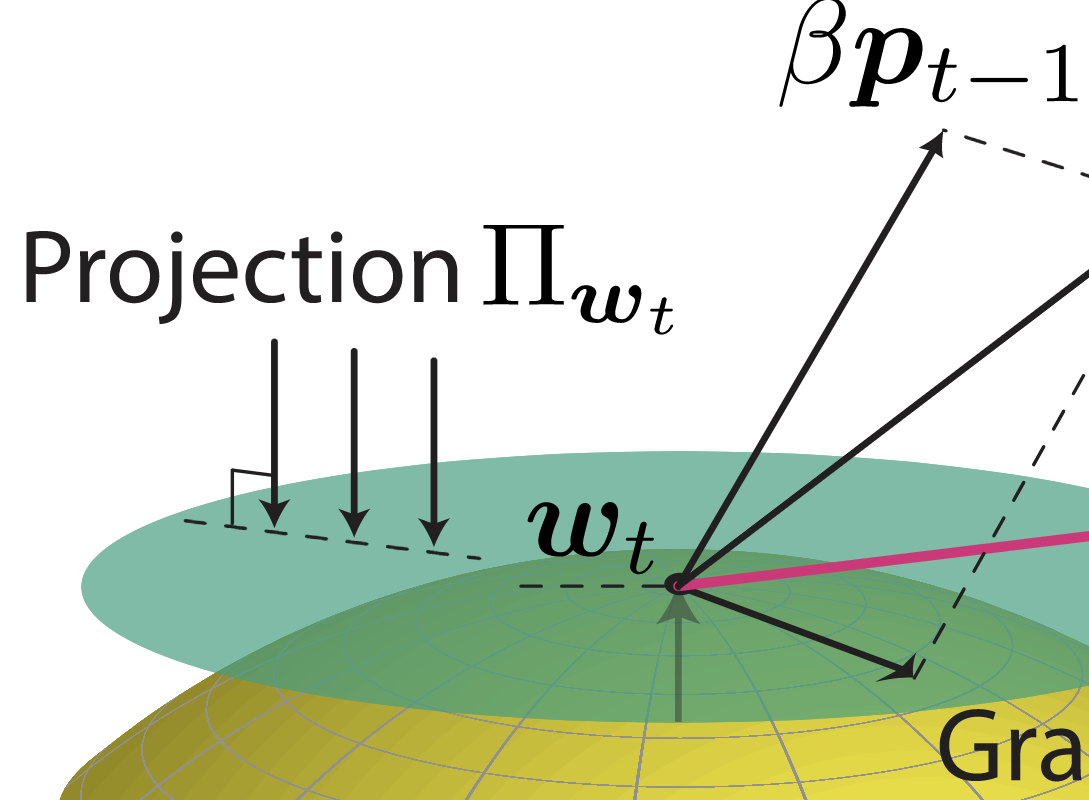
Byeongho Heo*, Sanghyuk Chun*, Seong Joon Oh, Dongyoon Han, Youngjung Uh, Sangdoo Yun, Jungwoo Ha. *Equal contribution ICLR, 2021 Bibtex / Code / Project Adding projection operation on Adam and SGD optimizer to mitigate slowdown of convergence due to rapidly increased norm. It leads to performance improvements across the board with easy installation (pip install adamp). |

|
Sangdoo Yun, Seong Joon Oh, Byeongho Heo, Dongyoon Han, Jinhyung Kim. arXiv, 2020 Bibtex Extension of CutMix to video recognition. We search for the best mixing strategy for video tasks. |
|
Hyojin Bahng, Sanghyuk Chun, Sangdoo Yun, Jaegul Choo, Seong Joon Oh, ICML, 2020 Bibtex / Code / ICML Virtual / Youtube Models tend to learn biased representations. To "de-bias" model representation, we "minus" biased representation from the target model. |
|
Youngjoon Yoo, Dongyoon Han, Sangdoo Yun. arXiv, 2019 Bibtex / Code Face detector has multi-stage for multi-resolution, but it indeed does not require such complex feature encoding. We introduce an extremely tiny face detector via iterative filter reuse. |

|
Sangdoo Yun, Dongyoon Han, Seong Joon Oh, Sanghyuk Chun, Junsuk Choe, Youngjoon Yoo. ICCV, 2019 (Oral Presentation) Bibtex / Code / Talk / Poster / Blog Simple cut-and-paste strategy brings significant performance boosts across tasks and datasets. |

|
Jeonghun Baek, Geewook Kim, Junyeop Lee, Sungrae Park, Dongyoon Han, Sangdoo Yun, Seong Joon Oh, Hwalsuk Lee. ICCV, 2019 (Oral Presentation) Bibtex / Code Scene text recognition evaluation has been somewhat wrong because the model and dataset were not controlled. We provide unified benchmark protocol and fairly reproduced results. We also found a new architecture from those unified experiments. |
|
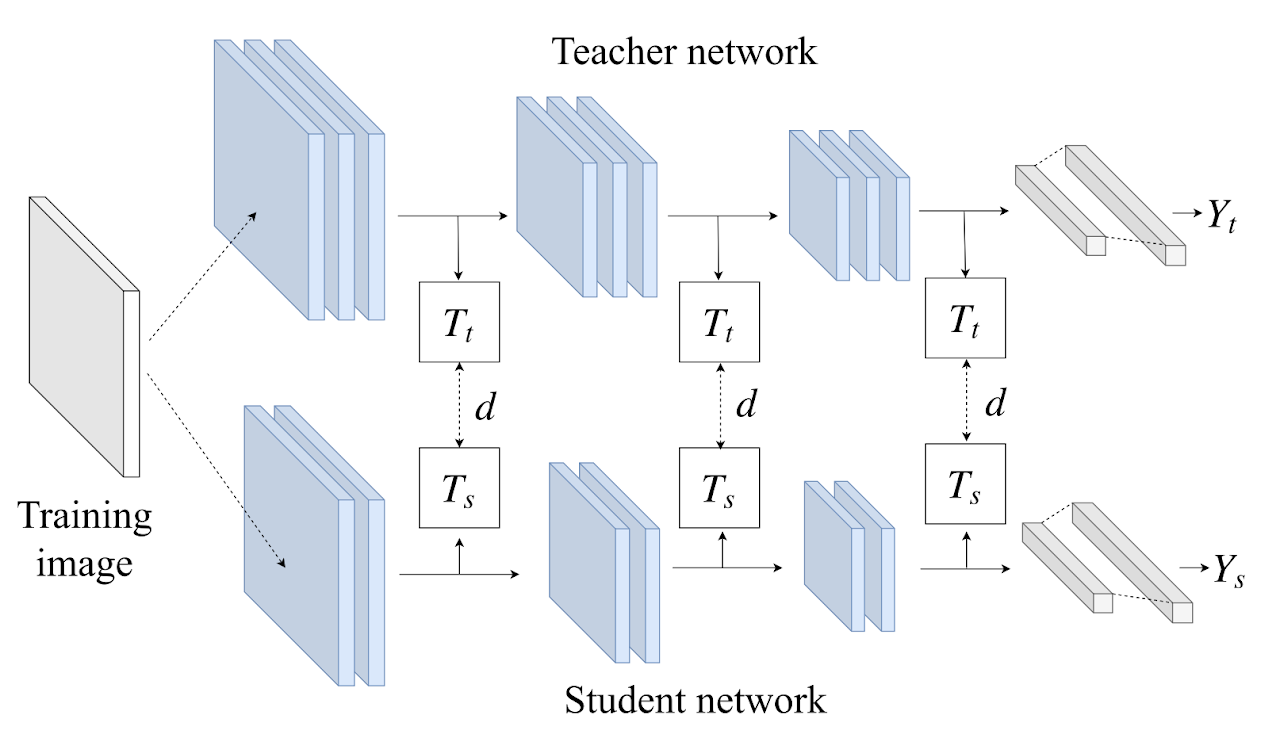
Byeongho Heo, Jeesoo Kim, Sangdoo Yun, Hyojin Park, Nojun Kwak, Jin Young Choi. ICCV, 2019 Bibtex / Code There are lots of options for feature distillation: loss function, distillation position, teacher/student transforms. We study all the possible methods and provide comprehensive overhaul for feature distillation. Through this, we found the best feature distillation method which even beats the teacher's accuracy. |
|
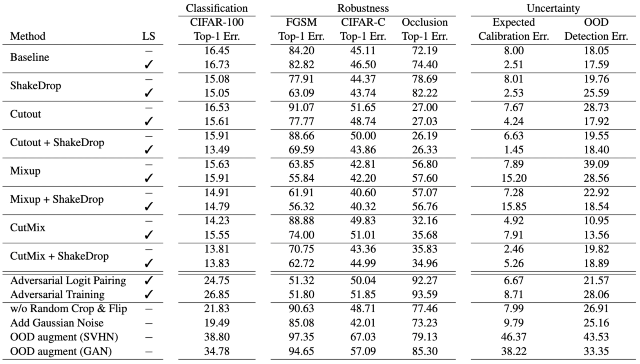
Sanghyuk Chun, Seong Joon Oh, Sangdoo Yun, Dongyoon Han, Junsuk Choe, Youngjoon Yoo. ICML Workshop, 2019 Bibtex We provide structured experimental results for the effectiveness of regularization methods on robustness and uncertainty benchmarks. |

|
Youngmin Baek, Bado Lee, Dongyoon Han, Sangdoo Yun, Hwalsuk Lee. CVPR, 2019 Bibtex / Code Text detectors often fail to detect real-world scene-texts, e.g., curved or long texts. We propose a two-stage approach; first detect individual characters and connect them. We also introduce semi-weakly-supervised training trick to boost our detector's performance. |
|
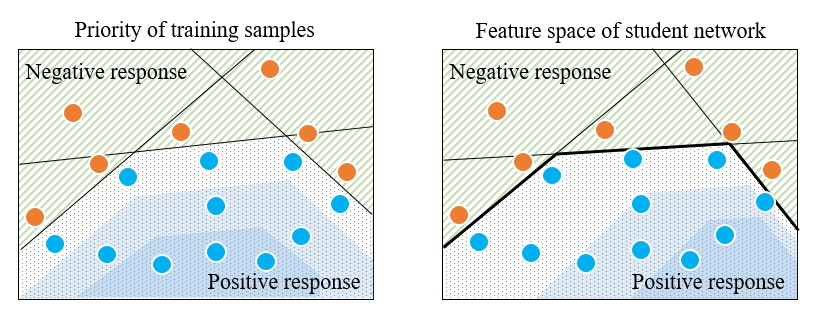
Byeongho Heo, Minsik Lee, Sangdoo Yun, Jin Young Choi. AAAI, 2019 (Oral Presentation) Bibtex / Code Previous feature distillation approach (e.g. FitNet) focuses on mimicking the teacher's feature values. Rather, our goal is to transfer the actual "activation boundary" by assigning binary labels (i.e. activated or not) for all the neurons. Our loss minimizes the binary-labels' similarity. It shows outperforming performance against state-of-the-art KD methods. |
|
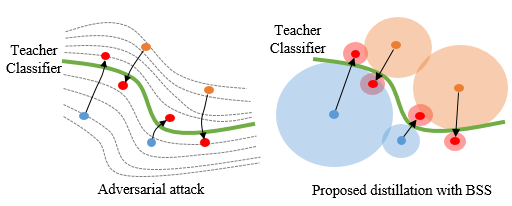
Byeongho Heo, Minsik Lee, Sangdoo Yun, Jin Young Choi. AAAI, 2019 Bibtex / Code To find teacher network's decision boundary more precisely, we adopt adversarial attack technique. We show the attacked samples improve distillation performance. |

|
Donghoon Lee, Sangdoo Yun, Sungjoon Choi, Hwiyeon Yoo, Ming-Hsuan Yang, Songhwai Oh ECCV, 2018 Bibtex / Code We train a GAN model that generates a holistic image from its small parts. |
|
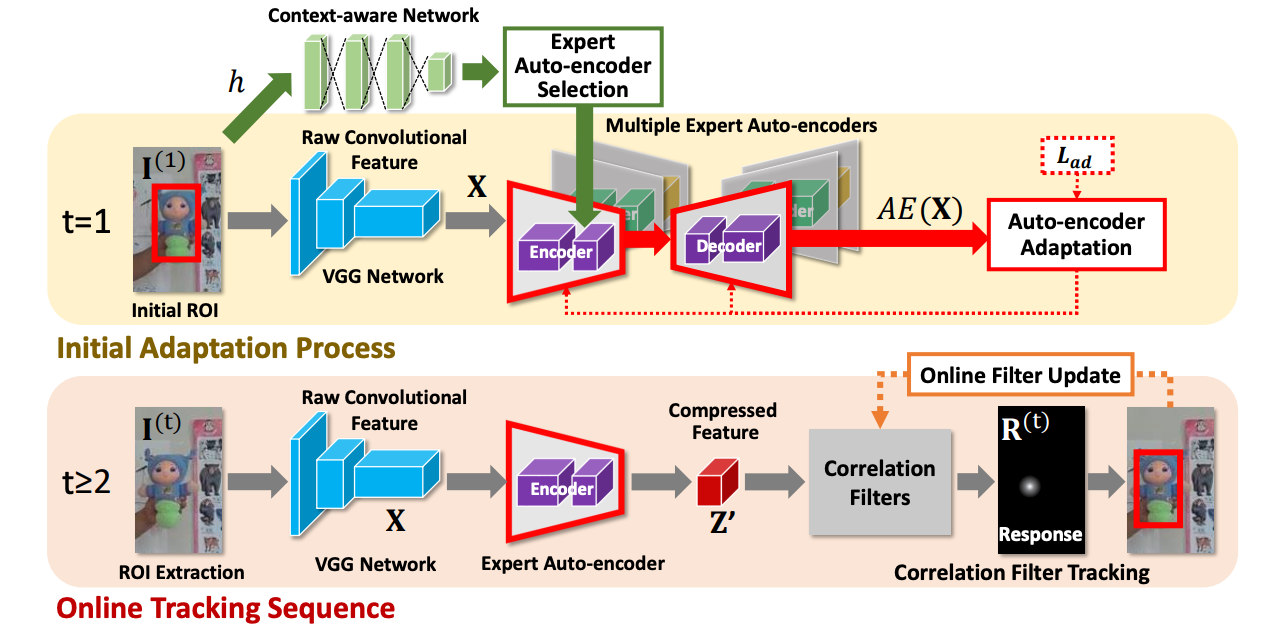
Jongwon Choi, Hyung Jin Chang, Tobias Fischer, Sangdoo Yun, Kyuewang Lee, Jiyeoup Jeong, Yiannis Demiris, Jin Young Choi. CVPR, 2018 Bibtex / Code Correlation-based trackers have shown promising performance using hand-crafted features (e.g., HOG). When adopting deep features for correlation-based trackers, the bottleneck is the computing costs for CNN feature extraction. We propose a deep feature compression method for high-speed and high-accuracy visual tracker. |
|
Sangdoo Yun, Jongwon Choi, Youngjoon Yoo, Kimin Yun, Jin Young Choi. TNNLS, 2018 Bibtex / Code A journal extension of ADNet (CVPR'17). |
|
|
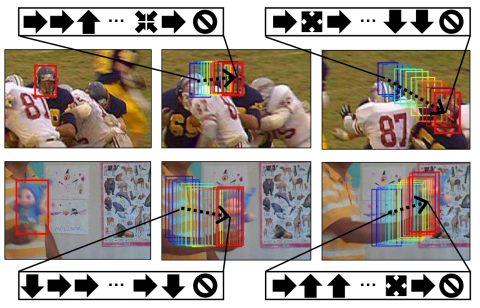
Sangdoo Yun, Jongwon Choi, Youngjoon Yoo, Kimin Yun, Jin Young Choi. CVPR, 2017 (Spotlight Presentation) Bibtex / Code We fomulate visual tracking as a decision making process and propose a reinforcement learning method to train visual trackers. Our RL-based tracker shows state-of-the-art level performance and especially it shows high efficiency with semi-supervised scenario. |
|
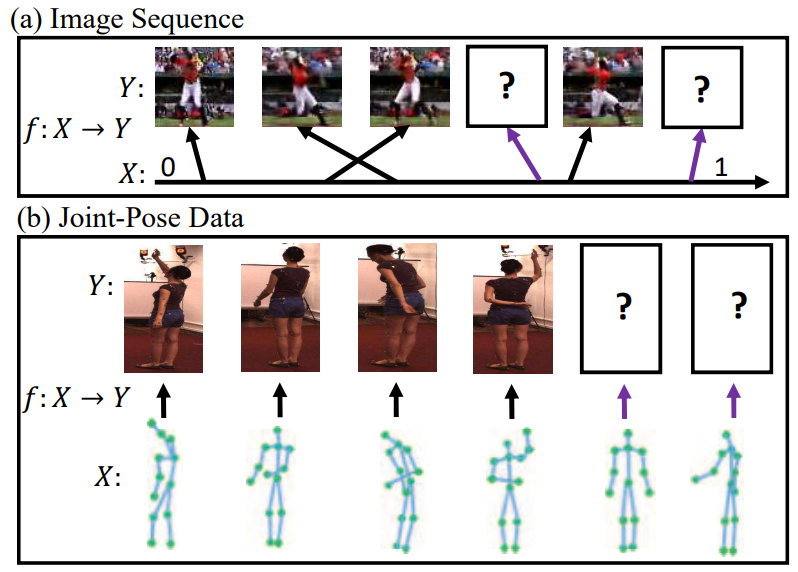
Youngjoon Yoo, Sangdoo Yun, Hyung Jin Chang, Yiannis Demiris, Jin Young Choi. CVPR, 2017 Bibtex / Code Generating visual data from given condition (e.g. frame index, pose skeleton, etc.) is difficult due to the visual data's high dimensions. Our idea is to regress the visual data in latent space which is encoded by VAE. Our method can generate high-quality visual data from frame index or pose skeletons. |
|
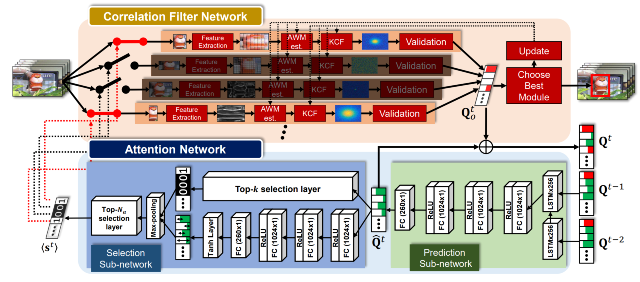
Jongwon Choi, Hyung Jin Chang, Sangdoo Yun, Tobias Fischer, Yiannis Demiris, Jin Young Choi. CVPR, 2017 Bibtex / Code Correlation-filter-based trackers usually use pre-defined feature extractor (e.g., color, edge, etc). Using more correlation filters with diverse feature extractors at the same time will bring higher accuracy, but it induces speed-accuracy trade-off. This work extends the number of correlation filters more than one hundred for maximizing accuracy. To deal with heavy computation, we introduce a LSTM-based attentional filter selection approach. Our method the state-of-the-art performance amongst real-time trackers. |

|
Junho Cho, Sangdoo Yun, Kyoung Mu Lee, Jin Young Choi. CVPR Workshop, 2017 Bibtex We propose a image colorization method from the given palette. |
|
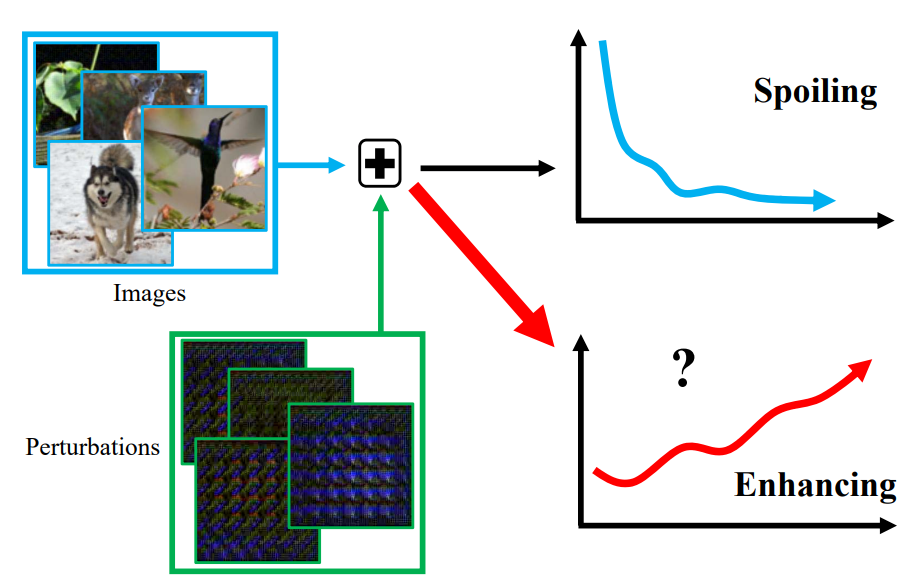
Youngjoon Yoo, Seonguk Park, Junyoung Choi, Sangdoo Yun, Nojun Kwak. arXiv, 2017 Bibtex This paper proposes a new algorithm for controlling classification results by generating a small perturbation without changing the classifier network. We show that the perturbation can degrade the performance like adversarial attack, or can improve classification accuracy as well. |
|
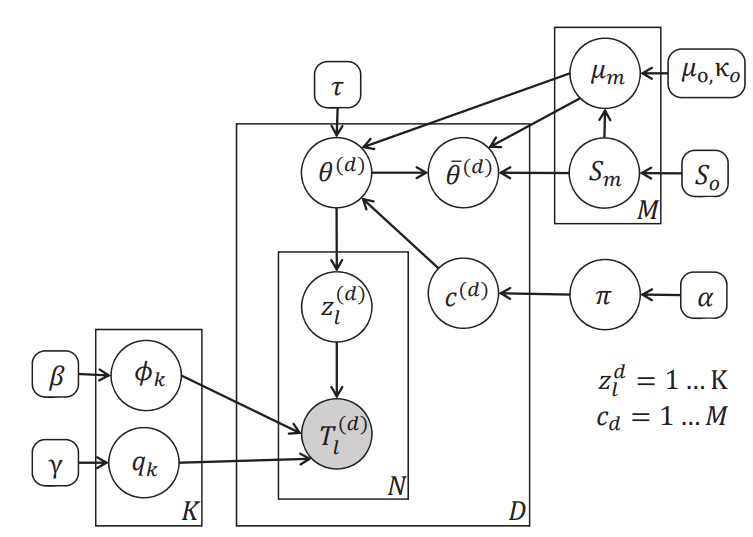
Youngjoon Yoo, Kimin Yun, Sangdoo Yun, JongHee Hong, Hawook Jeong, Jin Young Choi. CVPR, 2016 Bibtex Learn latent Dirichlet allocation model from the trajectory of people and predict future paths of people. |
|
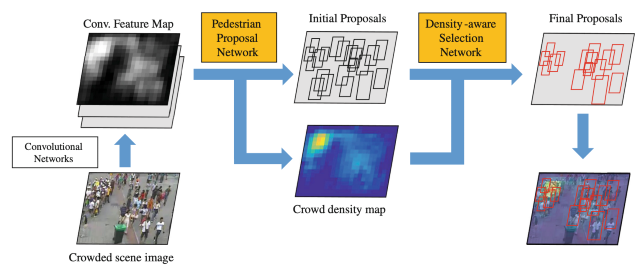
Sangdoo Yun, Kimin Yun, Jongwon Choi, Jin Young Choi. ECCV Workshop, 2016 Bibtex Detecting people in crowded scene by considering crowd density information. Our intuition is more people should be detected in crowded region. |
|
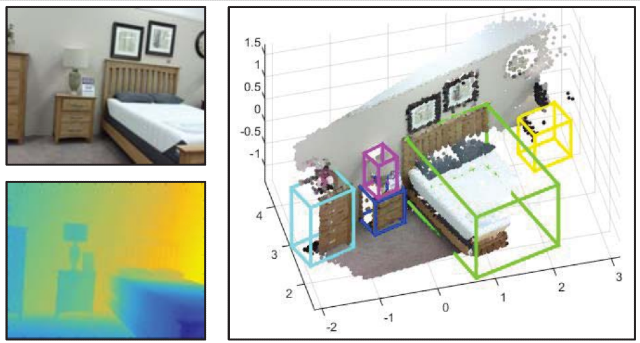
Sangdoo Yun, Hawook Jeong, Soo Wan Kim, Jin Young Choi. WACV, 2016 Bibtex Predicting holistic 3D structure from pratially occluded RGB-D images. The key idea is a voting mechanism. Each part of an object indicates the center of the 3D structure. |
|
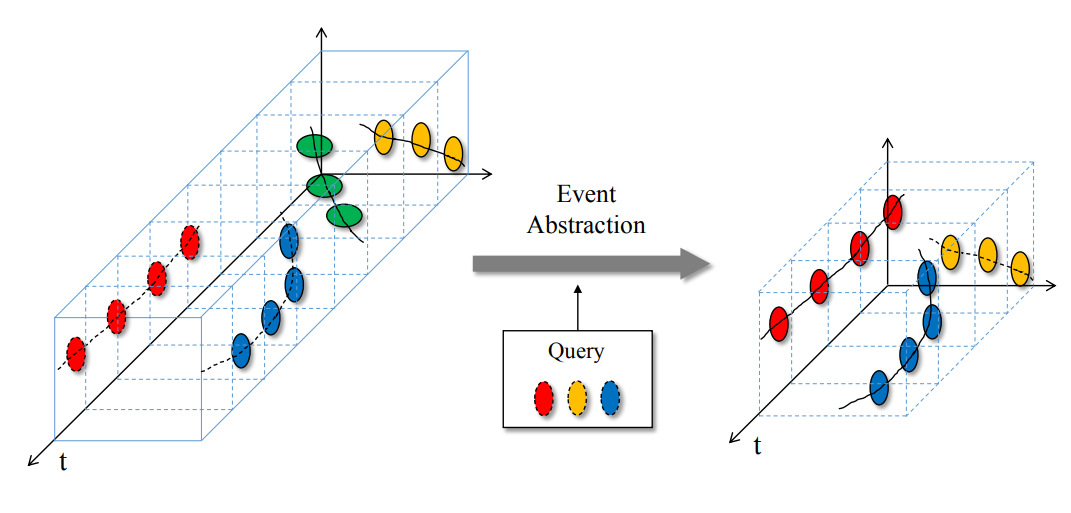
Sangdoo Yun, Kimin Yun, Soo Wan Kim, Youngjoon Yoo, Jiyeoup Jeong. AVSS, 2014 (Oral Presentation) Bibtex We propose a Visual Surveillance Briefing (VSB) system which generates summarized video with important events. |

|
Sangdoo Yun, Hawook Jeong, Woo-Sung Kang, Byeongho Heo, Jin Young Choi. ICPR, 2014 Bibtex We improve the computational efficiency of deformable part model (DPM) by re-organizing the order of part filters. With a cascaded structure, we place more important part filter at first for early rejection. |
|
Sangdoo Yun, Soo Wan Kim, Kwang Moo Yi, Haan-ju Yoo, Jin Young Choi. IVCNZ, 2012 (Oral Presentation) Bibtex Ground plain estimation is important for 3D scene understanding. Usually models assume the scene has a single ground plain, but sometimes it has multiple ground planes. We introduce multiple ground plane estimation for more robust scene understanding. |
{kind=link}
|
|

|
Zeynep Akata, Lucas Beyer, Sanghyuk Chun, Almut Sophia Koepke, Diane Larlus, Seong Joon Oh, Rafael Sampaio de Rezende, Sangdoo Yun, Xiaohua Zhai. NeurIPS, 2021 Website / Virtual Page / Preview in CV News ImageNet has played an important role in CV and ML in the last decade. It was created to train image classifiers at first but it has become a go-to benchmark for model architecture and training techniques. We believe now is a good time to discuss the ImageNet and its future. The workshop's questions will be like: Did we solve ImageNet? What have we learned from ImageNet? What should the next-generation ImageNet-like dataset be? |
| Reviewing activities |
Talks
|
|
Template borrowed from Jon Barron and Seong Joon Oh. |